


最高のSQL-on-Hadoopツールに興味をお持ちですか?前回の記事「8 SQL-on-Hadoop Challenges」では、SQLとHadoopという2つのテクノロジー間のギャップを埋めるのに役立ついくつかのツールの概要を説明しましたが、あまり詳細には触れませんでした。今回は、SQLをHadoopにもたらしてくれる12のツールについて、オープンソースと商用のソリューションの両方を網羅して紹介します。
これらのツールは、価格、機能、有用なユースケース、アクセス性、将来性などの理由から選んだものです。それでは、SQL-on-Hadoopに不可欠な12のツールをご紹介します。
Table of Contents
オープンソースのSQL-on-Hadoopツール
1. Apache Hive

Apache Hiveは、SQL-on-Hadoopツールの中でもトップレベルのツールです。当初Facebookによって開発されたHiveは、Hadoop上に構築されたデータウェアハウス基盤です。HDFSに格納されたデータをHQL(MapReduceのジョブに翻訳されたSQLのような言語)を介して、分析のためのクエリを実行することができます。
SQL機能を提供しているように見えますが、HiveはHadoop上でバッチ処理を行い、インタラクティブなクエリ機能は提供していません。メタデータをリレーショナルデータベースに格納し、そのデータに対してスキーマを維持する必要があります。 Hiveはいくつかのファイル形式をサポートしており、ユーザー定義ファンクションとともにHadoop上で圧縮データを処理することもできます。
要点:HiveはSQLライクな言語でHadoop上でのバッチ処理を提供します。
Hive vs. HBaseをどっちを選ぶべきか迷ってますか?こちらのブログ「Hive vs. HBase 比較」をチェックしてください。
2. Apache Sqoop
最も価値のあるSQL-on-Hadoopツールの一つであるApache Sqoopは、Javaでデータベースに接続するための標準APIであるJDBCを介して、リレーショナルデータベースからHadoopへのデータのインポートとエクスポートを可能にします。関連するツールでデータの一括インポート/エクスポートが可能な場合には、JDBCなしでも動作します。
Sqoopは、リレーショナルデータベース上でクエリを実行し、結果の行をテキスト、バイナリ、Avro、シーケンスファイルのいずれかの形式でファイルにエクスポートすることで動作します。これらのファイルはHadoopのHDFSに保存され、Hadoopからリレーショナルデータベースに戻すこともできます。最後に、SqoopはHadoop用のテーブルおよびストレージ管理サービスであるHCatalogと統合されており、HiveまたはPig経由でSqoopのインポートされたファイルを照会することができます。(詳細はSqoopのブログ記事を参照してください)。
要点: Sqoopを使うと、SQLデータベースからApache Hadoopにデータをインポートしたり、Apache Hadoopからデータをエクスポートしたりすることができます。


データを統一化して革新を起こすデータチームへ
ソリューションエンジニアによる個別デモと30分のQ&Aセッションを受けることができます
3. Apache Phoenix
![]()
Apache Phoenixは HBase 上での対話的なクエリのための SQLスキンです。SQLクエリを一連の HBaseスキャンにコンパイルし、JDBC の結果セットを生成します。
Phoenix は、スクラッチから構築するか、既存の HBase テーブルからマップしたスキーマを維持する必要がある点に注意してください。さらに、Phoenix がサポートしていない機能がいくつかあります: 完全なトランザクションのサポート、派生テーブル、一部のリレーショナル演算子(Intersect、Minus)、および雑多なビルトイン関数 (手動で追加することはできますが)。このプロジェクトは主にSalesforce、Intel、Hortonworksによってメンテナンスされています。
要点: Apache Phoenix は HBase 上で対話的な SQLクエリを提供します。
4. Apache Impala

Apache ImpalaはHadoopの上で動作し、HDFSとHBase上でインタラクティブなSQLクエリを実行するクエリエンジンです。バッチ処理を使用するApache Hiveとは異なり、Impalaはリアルタイムでクエリを実行するため、SQLベースのビジネスインテリジェンスツールとHadoopを統合することができます。
元々はエンタープライズデータクラウド企業のClouderaによって開発されたImpalaは、その後Apacheのオープンソース・ソフトウェア・エコシステムの一部となっています。Impalaは、テキスト、LZO、シーケンスファイル、Avro、RCFileを含む、すべての標準的なHadoopファイルフォーマットをサポートしています。また、ImpalaはAmazon Elastic MapReduce (EMR)を介してクラウド上で実行することも可能です。
要点: Impalaは、HDFSとHBaseを介した対話型SQLクエリのためのオープンソースソリューションです。
5. Apache Spark SQL

Apache Spark SQL は、オープンソースのビッグデータ処理エンジンであるApache Sparkのモジュールで、Sparkプログラム内で構造化されたデータをクエリするのに役立ちます。これは、数年前に頓挫したApache Spark用の大規模データウェアハウスシステムであるApache Sharkの後継モジュールです。
Spark SQLでは、DataFramesと呼ばれる概念が導入されており、リレーショナルデータベースのテーブルと同等のもので、追加の機能強化と最適化が施されています。Spark SQLモジュールは、Hive、Avro、Parquet、ORC、JSON、JDBCを含む多くの異なるデータソースおよび、Java、Scala、Python、Rを含むプログラミング言語と互換性があります。
要点: Apache Spark SQLは、Apache Spark内でSQL-on-Hadoop機能が必要な場合に最適な選択肢です。
6. Apache Drill
![]()
Apache Drillは 「Hadoop、NoSQL、クラウドストレージのためのスキーマフリーのSQLクエリエンジン」と謳っています。Drillは、複雑で入れ子になったデータや非リレーショナルテーブルに対するSQLクエリを可能にするJSONデータモデルを利用しています。Drillでは、リレーショナルデータベースにクエリを実行するのと同じように、標準的なSQLクエリを使用することができます。
オープンソースの Drill プロジェクトは、大規模で分散したデータセットをクエリするための Google の Dremel システムをベースにしています。DrillにはREST APIがあり、Tableau、Qlik、SAS、Microsoft Excelなどのビジネスインテリジェンスアプリケーションと統合されています。
要点: Apache Drill はSQLを使用して Hadoop や NoSQL データベースをクエリすることができます。
データを統一化して革新を起こすデータチームへ
ソリューションエンジニアによる個別デモと30分のQ&Aセッションを受けることができます
7. Presto
Presto は、Hive、HBase、さらにはリレーショナルデータベースや独自のデータストアの上で動作するインタラクティブな SQL クエリエンジンで、企業や組織全体で複数のソースからのデータを結合するのに役立ちます。プロジェクトのウェブサイトによると、Prestoは「Hadoop上で最も高速なSQLエンジン」であり、それを裏付けるベンチマークがあります。
FacebookはPrestoの主な開発者であり、同社は300ペタバイトのデータウェアハウスを含む社内のデータストアに対するクエリにそれを使用しています。AirbnbやDropboxのような他の大企業も、技術スタックでPrestoを使用しています。
要点: Presto は、Hive や HBase を介した対話的な SQL クエリのための Facebook のエンタープライズクラスのソリューションです。
8. Citusdata
Citus Data (CitrusDBと混同しないように注意ください。)は、Hadoop上で動作するSQLライクな機能を持つもう一つの対話型クエリエンジンです。Citusは、ビッグデータを処理するためのリアルタイム分析データベースのGoogle版であるDremelをベースにしています。2019年にMicrosoftに買収されて以来、Citusはオープンソースのソフトウェアとして、またAzure Database for PostgreSQLのHyperscale(Citus)のデプロイメントオプションとして利用できるようになりました。
ImpalaやPrestoとは異なり、Citusは裏側で動作するSQLエンジンとしてPostgreSQLを使用しています。Citusはオンプレミスでもクラウドでも実行でき、全文検索、ジオ検索、ODBC/JDBC互換性などの機能をサポートしています。分析データベースであるCitusは、データの一括読み込みしかサポートしていません。
要点:CitusはPostgreSQLを使ったSQL-on-Hadoopの対話型のクエリを提供しています。
商用ライセンスのSQL-on-Hadoopツール
9. Jethro
Jethroは、データがHadoopに書き込まれるとすぐに自動的にインデックスを作成するHadoop用のSQLエンジンを提供することで、「BIのための最速のSQL-on-Hadoopエンジン」を提供すると謳っています。Jethroのウェブサイトによると、このツールはHiveやImpalaなどのツールよりも「最大100倍速いクエリ」を提供できると述べています。インストールと使用方法は簡単です。Jethroは既存のHadoopクラスタに追加することができ、侵入することもなく、Hadoopストレージノードにインストールする必要もありません。
要点: Jethroは、自動インデックスにより、高速で利用者に負担のかからないSQL-on-Hadoopを提供します。
10. HAWQ
HAWQ は、EMCの子会社であるPivotal社の商用SQL-on-Hadoopプラットフォームです。PivotalのGreenplum Analytic DatabaseとHadoopのHDFSをデータストレージに使用した並列SQLクエリエンジンを提供します。HAWQエンジンは、フルトランザクションをサポートしたアナリティクスに有用で、テキスト、Hive、HBase、Parquetを読み取る外部テーブルをHDFS上で作成する機能をサポートしています。
要点:HAWQはPivotalのSQL-on-Hadoopソリューションです。
11. BigSQL

Big SQL by IBM (Postgres by BigSQLと混同されないように、現在は廃止されているようですが、オープンソースのプロジェクトです) は、大規模並列処理(MPP)や高度なデータクエリのためのIBMのSQL-on-Hadoopエンジンです。IBM Big SQLを使用して、リレーショナル・データベース、NoSQL データベース、HDFS、オブジェクト・ストアなど、さまざまな形式にアクセスすることができます。
IBM Big SQLは、クラスタ内の複数のノードにクエリを分散させることで、クエリのパフォーマンスを向上させます。Big SQLのユースケースには、既存の Oracle や IBM データウェアハウスからのデータのオフロードや、Hadoop に移行できないデータが保存されたリレーショナル・データベースへのフェデレーティッド・アクセスなどがあります。
要点: IBM Big SQLは、大企業向けに Hadoop 上の堅牢な SQL ツールを提供します。
データを統一化して革新を起こすデータチームへ
ソリューションエンジニアによる個別デモと30分のQ&Aセッションを受けることができます
12. PolyBase
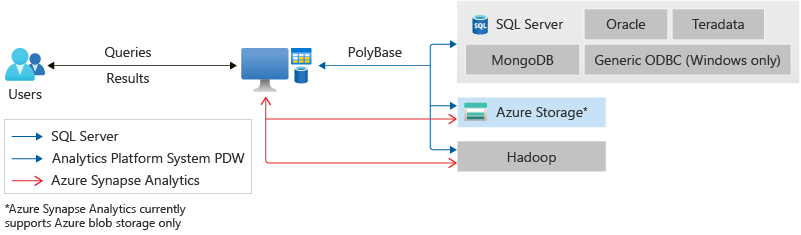
PolyBaseは、SQLクエリを処理するためのMicrosoftのSQL-on-Hadoopツールです。Microsoft SQL Serverのお客様は、PolyBaseを使用して、HadoopやAzure Blob Storage、SQL Server、Oracle、Teradata、MongoDBデータベースのデータにアクセスできます。
Transact-SQL言語を使用することで、PolyBaseのユーザーは、Hadoopに格納されたデータをクエリしたり、Hadoopからデータをインポートしたり、Hadoopにデータをエクスポートしたりすることができます。PolyBaseのクエリオプティマイザは、計算をHadoopにプッシュするかどうかを判断し、Hadoopの分散性を活かしたMapReduceジョブを作成することができます。
要点: PolyBase は、Microsoft SQL Server のユーザーにとって強力な SQL-on-Hadoop ツールです。
SQL on Hadoopのガイダンスをお探しですか? Integrate.ioがサポートします。
Hadoopの世界のビッグデータガイドが必要ですか?Integrate.ioのデータ統合のエキスパートは、ビッグデータのワークフローを最適化する方法を知っています。私たちのクラウドベースのETL(extract, transform, load)ソリューションは、膨大な範囲のソースとデスティネーションにわたって自動化されたデータフローのためのシンプルで可視化されたデータパイプラインを提供します。
Integrate.ioのHPにアクセスし、オンラインデモとリスクフリーのトライアルをスケジュールし、Integrate.ioプラットフォームの使い勝手をご自身で体験してみてください。



