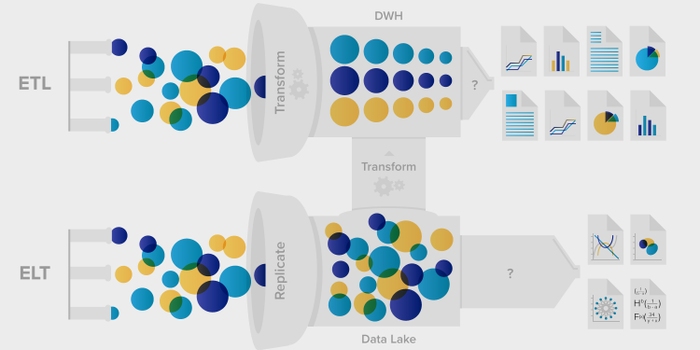

データ管理の世界では、ETL(Extract-Transform-Load)とELT(Extract-Load-Transform)の議論は、ますます関連性の高いトピックとなっています。本質的な違いは、操作の順序にある: ETLはデータウェアハウスに入る前にデータを処理するのに対し、ELTはデータウェアハウスのパワーを活用し、ロード後にデータを変換します。デジタル環境が進化し続ける中、この2つの方法論の決定的な違いを理解することは、データ変換戦略を最適化する上で不可欠となります。
ETLとELTはどちらもデータ統合に不可欠なプロセスですが、そのアプローチには独特の違いがあります。ETLは、ソースからステージング、そしてデータウェアハウスへとデータを移動させる手法で複雑なデータ変換を可能にして費用対効果を高めます。一方、ELTはデータウェアハウスの機能を変換に利用するため、データステージングが不要になり、データ処理が高速化する可能性があります。
しかし、このトピックの複雑さは、単純な順序付けにとどまらないです。この記事では、データのプライバシーやコンプライアンスに関する考慮事項から費用対効果まで、ETLとELTの5つの決定的な違いについて掘り下げ、お客様のデータニーズに合わせた情報に基づいた意思決定を行うための包括的なガイドを提供します。
ETL vs ELT 5つの重要な違い:
- ETLとは、Extract(抽出)、Transform(変換)、Load(読み込み)の頭文字をとったものです。ELTは、Extract、Load、Transformの意味です。どちらもデータ統合のためのプロセスである。
- ETL方式では、データはデータソースからステージング、そしてデータウェアハウスに移動します。
- ELTでは、データウェアハウスを活用して基本的な変換を行います。データステージングは必要ありません。
- ETLは、データウェアハウスにロードする前に機密データやセキュアなデータをクリーニングすることで、データのプライバシーとコンプライアンスに貢献します。
- ETLは高度なデータ変換を行うことができ、ELTよりも費用対効果が高い場合があります。
- ETLとELTの説明は簡単ですが、全体像、つまりETLとELTの潜在的な利点を理解するには、ETLがデータウェアハウスでどのように機能するか、ELTがデータレイクでどのように機能するかについて、より深い知識が必要です。
目次


データを統一化して革新を起こすデータチームへ
ソリューションエンジニアによる個別デモと30分のQ&Aセッションを受けることができます
ETLおよびELT概要
ETLとELTの違いを説明するのは簡単ですが、全体像、つまりETLとELTの潜在的な利点を理解するには、ETLがデータウェアハウスでどのように機能し、ELTがデータレイクでどのように機能するかについての深い知識が必要です。

情報ソースが構造化されたSQLデータベースであろうと、構造化されていないNoSQLデータベースであろうと、同じ形式や互換性のある形式を使用することはほとんどないため、ETLとELTはどちらもデータサイエンスにおいて必要な統合手法です。そのため、データソースを分析可能な全体像に統合する前に、データソースをクリーニング、エンリッチ、変換する必要があります。そうすれば、ビジネスインテリジェンスプラットフォーム(Looker、Chartio、Tableau、QuickSightなど)がデータを適切に理解し、ビジネスの成功を促進する実用的な洞察を導き出すことができます。
これまで述べてきたように、データ管理者がETLとELTのどちらを使用しているかにかかわらず、データ変換と統合のプロセスには次の3つのステップが含まれます:
- 抽出: 抽出とは、元のデータベースやデータソースからソースデータを取り出すことを指します。ETLの場合、データは一時的なステージング・エリアに置かれます。ELTの場合、データはすぐにデータレイクやデータウェアハウスのストレージシステムに格納されます。
- トランスフォーム: 変換とは、情報の構造と形式を変更するプロセスのことで、ターゲットとなるデータシステムおよびそのシステム内の他のデータと統合されるようにします。
- ロード(Load): ロードとは、情報をデータストレージシステムに預けるプロセスを指します。
ETLとELTは、これらのステップを互いに異なる順序で実行することは、すでに確認済みです。そこで問題なのは、データをデータリポジトリにロードする前と後、どちらでデータを変換すべきかということです。それに答えるには、ETLとELTを別々に理解する必要があります。
続きを読む: ETL Methodologies: A Guide to Our Data Warehouse Integration Platform
ETLのプロセスを詳しく解説します: ETLとは?

オンライン分析処理(OLAP)データウェアハウスは、クラウドベースかオンサイトかにかかわらず、リレーショナルSQLベースのデータ構造で動作する必要があります。したがって、OLAPデータウェアハウスにロードするデータは、データウェアハウスがデータを取り込む前に、リレーショナル形式に変換する必要があります。このデータ変換プロセスの一環として、相関する情報に基づいて複数のデータソースを結合するデータマッピングも必要になる場合があります。これは、ビジネスインテリジェンスプラットフォームが、情報を単一の統合ユニットとして分析できるようにするためです。
データウェアハウスの種類によってはETLが必要なのは、データを読み込む前に変換を行う必要があるからです。ここでは、ETLについて理解するためのいくつかの詳細を説明します:
- ETLは、明確に定義されたワークフローを持つ、継続的なプロセスである必要があります:ETLはまず、同種または異種のデータソースからデータを抽出します。ETLはまず、同種または異種のデータソースからデータを抽出し、次にそのデータをステージング・エリアに預けます。そこからデータはクレンジングプロセスを経て、強化・変換され、最終的にデータウェアハウスに格納されます。
- 以前は、データエンジニアや開発者による詳細な計画、監督、コーディングが必要でした: データウェアハウスのETL変換を手作業でコーディングする旧来の方法には、膨大な時間がかかっていました。プロセスを設計した後でも、データウェアハウスを新しい情報で更新する際に、データが各段階を通過するのに時間がかかっていました。
- 最新のETLソリューションは、より簡単で高速です: 最新のETL、特にクラウドベースのデータウェアハウスやクラウドベースのSaaSプラットフォームでは、より高速に処理することができます。クラウドベースのETLソリューションを使用することで、ユーザーはプログラミングの専門知識がなくても、多様なソースからデータを即座に抽出、変換、ロードすることができます。
Integrate.ioは、超高速のチェンジデータキャプチャ(CDC)やリバースETL機能など、さまざまな業種の企業にデータ統合のオプションを提供する新しいETLプラットフォームです。
続きを読む: リバースETL:知っておくべきこと
ETLの最大のメリット
ELTに対するETLの最大の利点は、OLAPデータウェアハウスの構造化済みの性質に関連している。ETLは、データを構造化・変換した後、より迅速で効率的、かつ安定したデータ分析を可能にします。これに対してELTは、ロードしたばかりのデータをスピーディーに分析する必要がある場合には不向きである。
ELTと比較した場合のETLのもう一つの大きな利点は、コンプライアンスに関連することです。GDPR、HIPAA、CCPAなどの規制を受ける企業では、顧客のプライバシーを守るために、特定のデータフィールドを削除、マスク、暗号化する必要があることがよくあります。例えば、電子メールをドメインのみに変換したり、IPアドレスの最後の部分を削除したりすることがあります。ETLは、データウェアハウスに入れる前にデータを変更するため、こうした変換をより安全に実行することができます。私たちのプラットフォームはセキュリティに非常に重点を置いており、高度に安全な変換によって個人を特定できる情報(PII)を保護し、転送中のデータへのリスクを最小限に抑え、データ侵害の可能性を低減しています。
一方、ELTでは、機密性の高いデータを最初にアップロードする必要があります。そのため、シスアドがアクセスできるログに表示されることになります。また、ELTを使用してデータを変換すると、データレイクにアップロードする際に非準拠のデータがEUを離れると、EUのGDPRコンプライアンス基準に不注意で違反する可能性があります。これは、グローバルに事業を展開する企業にとって、特に重要な検討事項です。最終的に、ETLはコンプライアンス違反のリスクを低減します。なぜなら、コンプライアンス違反のデータが誤ってデータウェアハウスやレポートに混入することがないからです。
最後に、データ統合・変換プロセスとして、ETLは20年以上前から存在しています。つまり、データの抽出、変換、ロードのニーズを支援するために、多くのよく開発されたETLツールやプラットフォームが利用可能です。また、ETLパイプラインの設定に熟練した経験豊富なデータエンジニアは、フルタイムの雇用としては高価ですが、簡単に見つけることができます。このため、最新のクラウドベースのETLプラットフォームは、拡張可能な量のビッグデータを扱う必要のある企業にとって不可欠です。
ELTのプロセスを詳しく解説します: ELTとは何か?

ELTとは?
ELTとは 「Extract、 Load、 Transform」の略です。このプロセスでは、データウェアハウスを介してデータを活用し、基本的な変換を行います。つまり、データのステージングは必要ありません。ELTでは、構造化データ、非構造化データ、半構造化データ、さらにはローデータなど、あらゆる種類のデータに対応したクラウドベースのデータウェアハウスソリューションを使用します。
ELTのプロセスは、「データレイク」とも密接に関係しています。 「データレイク」は、OLAPデータウェアハウスとは異なり、あらゆる種類の構造化データまたは非構造化データを受け入れる特別な種類のデータストアです。データレイクでは、ロードする前にデータを変換する必要はありません。データ形式に関係なく、あらゆる種類の「未加工」情報をデータレイクにすぐにロードすることができます。
ビジネスインテリジェンスプラットフォームでデータを分析する前に、データ変換が必要となります。ただし、データをデータレイクにロードした後に、データのクレンジング、強化、および変換が行われます。それでは ELTとデータレイクについて見ていきましょう。
- 高速なクラウドベースのサーバーによって可能になった新しいテクノロジー:ELTは比較的新しいテクノロジーであり、最新のクラウドベースのサーバーテクノロジーによって実現可能になりました。クラウドベースのデータウェアハウスは、ほぼ無限のストレージ機能とスケーラブルな処理能力を提供します。たとえば、Amazon RedshiftやGoogle BigQueryのようなプラットフォームは、信じられないほどの処理能力によりELTパイプラインを可能にしています。
- どんなデータもすべて取り込む:ELTとデータレイクを組み合わせて、現在も拡大し続けている保管されたデータをすぐに取り込むことが可能です。またデータをデータレイクに保存する前に、データを特別な形式に変換する必要はありません。
- 必要なデータのみを変換:ELTは、特定の分析に必要なデータのみを変換します。データの分析プロセスは遅くなりますが、柔軟性が向上します。データをその場でさまざまな方法を使って変換し、さまざまな種類のメトリック、予測、レポートを作成できるためです。対照的にETLの場合は、事前に定義された構造が新しいタイプの分析に向かない場合、ETLパイプライン全体とOLAPウェアハウスのデータ構造を変更する必要があります。
- ELTはETLよりも信頼性が低い:ELTのツールとシステムはまだ進化しているため、OLTデータベースと組み合わせたETLほど信頼性がないことを頭に入れておく必要があります。ETLは構築により多くの労力がかかりますが、ETLは膨大なデータを処理する際により正確なインサイトを提供します。また、ELTテクノロジーを熟知しているELT開発者は、ETL開発者よりも見つけてくるのが難しいです。
ELTの最大の利点
ETLに対するELTの主な利点は、新規に非構造化データを格納する場合の柔軟性と容易さにあります。 ELTを使用すると、あらゆる種類の情報を保存できます。最初に情報を変換および構造化する時間や能力がなくても、必要なときにすべての情報にすぐにアクセスできます。さらに、データを取り込む前に複雑なETLプロセスを開発する必要がなく、開発者とBIアナリストが新しい情報を処理する時間を節約できます。
その他のELTのメリットをご紹介します。
メリット1:高速性
データの可用性という点では、ELTはより高速なオプションです。ELTでは、すべてのデータがすぐにシステムに入り、そこからユーザーは、変換と分析の両方に必要なデータを正確に判断することができます。
メリット2:低メンテナンス
ELTでは、一般的にユーザーは「ハイタッチ」のメンテナンスプランを持つ必要がありません。 ELTはクラウドベースであるため、ユーザーが手動で更新を行うのではなく、自動化されたソリューションを利用します。
メリット3:ローディングの高速化
ELTは、データがウェアハウスにロードされるまで変換ステップを行わないため、データを最終地点にロードする時間を短縮することができます。データのクレンジングやその他の修正を待つ必要がなく、ターゲットシステムに一度だけ入力すればよいのです。
ELTの最適な使用方法
この記事で説明したように、ETL vs ELTの比較は現在進行形で続けられており結論は出ていません。では、どのような状況でETLの代わりにELTの使用を検討すべきでしょうか?ここでは、そのいくつかをご紹介します。
利用例1:
膨大な量のデータを持つ企業。ELTは、構造化、非構造化を問わず、膨大な量のデータに最適です。対象となるシステムがクラウドベースである限り、ELTソリューションを使えば、膨大な量のデータをより迅速に処理することができるでしょう。
利用例2:
必要な処理能力に対応できるリソースがある企業。ETLでは、処理の大部分は、データがウェアハウスに届く前のパイプライン内で行われます。ELTでは、データがデータレイクに到着してから作業を行います。目的に応じてデータにどのような処理が必要かにもよりますが、中小企業の場合、データレイクのメリットを最大限に引き出すために必要な大規模なテクノロジーを開発・検討するだけの経済的な柔軟性がない場合もあります。
利用例3:
すべてのデータを早急に一か所に集めたい企業。変換がプロセスの最後に行われる場合、ELTはほとんどすべてのことよりも転送速度を優先します。つまり、良いデータも悪いデータもその他のデータも、すべてのデータが後の変換のためにデータレイクに入ってしまうのです。
データを統一化して革新を起こすデータチームへ
ソリューションエンジニアによる個別デモと30分のQ&Aセッションを受けることができます
ETL vs. ELT 比較表
| ETL | ELT | |
|
テクノロジーの浸透度とツールや専門家の可用性
|
20年以上に渡って使われてきたすでによく開発された手段です。ETLの技術者はすぐに見つけてくることができます。
|
新しいテクノロジーということで、技術者を見つけるのが難しく、データパイプライン開発がETLに比べて難しいといったことがあります。
|
|
システム内でのデータの可用性
|
データウェアハウスやETL処理を作成する際、事前に決めたデータについてのみ変換、ロードします。そのためデータの可用性は限定されます。
|
即座にロード可能であり、ユーザーは取り込んだ後にどのデータを加工したり利用すべきかを決めることができます。
|
|
計算項目を追加できるか?
|
計算は既存の列を置き換えるか、データセットに追加して計算結果をターゲットデータに送ることができます。
|
計算項目を既存のデータセットに直接追加することができます。
|
|
データレイクとの互換性
|
通常、データレイク向けのソリューションではありません。構造化されたリレーショナルなデータウェアハウスシステムと統合するためにデータを変換します。
|
非構造化データを取り込むためのデータレイクへのパイプラインを提供します。分析のために必要に応じてデータを変換します。
|
|
コンプライアンス
|
機密情報をデータウェアハウスやクラウドに格納する前に編集および削除できます。これにより、GDPR、HIPAA、およびCCPAコンプライアンス基準を満たすことが容易になります。また、データをハッキングや不注意な露出から保護します。
|
機密情報を編集/削除する前にデータがアップロードされます。これは、GDPR、HIPAA、およびCCPA標準に違反する可能性があります。機密情報は、ハッキングや不注意によるデータ漏洩といった問題に対してより脆弱な状況です。また、クラウドサーバーが別の国にある場合、一部のコンプライアンス基準に違反する可能性があります。
|
|
データサイズと変換処理の複雑さ
|
複雑な変換を必要とする小規模なデータセットを扱うのに最適です。
|
大量の構造化および非構造化データを処理する場合に最適です。
|
|
データウェアハウスに対応しているか?
|
クラウドベースおよびオンプレミスのデータウェアハウスと連携します。リレーショナルデまたは構造化データ形式である必要があります。
|
クラウドベースのデータウェアハウジングソリューションと連携して、構造化、非構造化、半構造化、および未加工のデータ形式をサポートします。
|
|
ハードウェア要件
|
クラウドベースのETLプラットフォーム(Integrate.ioなど)は、特別なハードウェアを必要としません。
昔からのオンプレミスETLには、膨大なリソースと高価なハードウェアが要件として求められる場合がありますが、現在はあまり一般的ではありません。
|
クラウドベースであり、特別なハードウェアを必要としません。
|
|
集計方法の違い
|
データセットのサイズが大きくなると、集計はより時間がかかります。
|
強力なクラウドベースのターゲット・データシステムがあれば、大量のデータをすばやく処理できます。
|
|
実装の難易度
|
専門家を容易に見つけてくることできます。プロジェクトを効率的に進めるために、高度に進化したETLツールを利用できます。
|
新しいテクノロジーとして、ELTソリューションツールはまだ発展途上にあります。必要なELTの知識とスキルを持つ専門家を見つけるのは容易ではありません。
|
|
メンテナンス
|
Integrate.ioのような自動化されたクラウドベースのETLソリューションにおいて、メンテナンスはほとんど必要ありません。ただし、物理サーバーを使用するオンプレミスETLソリューションでは、頻繁なメンテナンスが必要になります。
|
クラウドベースであり、通常は自動化されたソリューションが組み込まれているため、メンテナンスはほとんど必要ありません。
|
|
処理の順序
|
データ変換は、ステージング領域内で抽出した直後に発生します。変換後、データはデータウェアハウスにロードされます。
|
データが抽出され、最初にターゲットデータにロードされます。その後、分析のため「必要に応じて」データの一部が変換されます。
|
| 費用 |
セッションごとの課金モデル(Integrate.ioなど)で請求するクラウドベースのSaaS ETLプラットフォームは、使用要件に応じて、約100ドルからスタートする柔軟なプランを提供しています。一方、InformaticaのようなエンタープライズレベルのオンプレミスETLソリューションは、年間100万ドル以上かかる可能性があります。
|
セッションごとの課金モデルで請求するクラウドベースのSaaS ELTプラットフォームは、約100ドルからスタートする柔軟なプランを提供しています。 ELTのコスト上の利点の1つは、高額な料金を支払うことなくデータをロードおよび保存し、必要に応じて変換できることです。情報をロードして保存するだけであれば、これにより初期費用を節約できます。ただし、財政難の企業は、データレイクのメリットを最大限に活用するために必要な処理能力を確保できない場合があります。
|
|
変換処理
|
変換は、データウェアハウスではなく外部のステージングエリア内で行われます。
|
変換はデータシステム自体で内部的に行われるため、ステージング領域は不要です。
|
|
非構造化データのサポート
|
非構造化データを構造化するために使用できますが、非構造化データをターゲットシステムに渡すのには使用されません。
|
非構造化データをデータレイクにアップロードし、非構造化データをビジネスインテリジェンスシステムで利用できるようにするソリューションです。
|
|
データをロードするのにかかる時間
|
処理時間は、多段階のプロセスを経るため、ELTよりも長くなります。(1)ステージング領域へのデータロード、(2)変換の実行、(3)データウェアハウスへのデータロード。いったんデータがロードされると、データ分析はELTよりも高速に行われます。
|
変換の必要がなく、データがターゲットシステムにそのままロードされるため、データの処理時間が高速になります。ただし、データ分析はETLよりも遅くなります。
|
|
データを変換するのにかかる時間
|
すべてのデータがロード前に変換を必要とするため、最初はデータ変換に時間がかかります。また、データシステムのサイズが大きくなった場合も、変換に時間がかかります。ただし、変換されてシステム内に配置されると、迅速かつ効率的にデータ分析を行うことができます。
|
変換はロード後に必要に応じて行われるため、その時点で分析対象のデータのみを変換するため、変換は非常に高速に行われます。ただし、データを継続的に変換する必要があるため、クエリ/分析にかかる合計時間が遅くなります。
|
まとめ:
- ETLは、Extract(抽出)、Transform(変換)、Load(ロード)の略で、ELTはExtract(抽出)、Load(ロード)、Transform(変換)の略です。
- ETLでは、データはデータソースからステージング、そしてデータ転送先(デスティネーション)へと流れます。
- ELTでは、データ転送先で変換を実施します。データのステージングは不要です。
- ETLは、データのプライバシーやコンプライアンス、データ転送先にロードする前にセンシティブなデータをクレンジングするなどに役立ちますが、ELTは、それよりシンプルで、マイナーなデータニーズを持つ企業に適しています。
データ活用に力を
もしあなたがデータ統合のボトルネックに悩んでいるなら、Integrate.ioの自動化されたETLプラットフォームは、クラウドベース、ビジュアル、ノーコードのインターフェイスを提供し、データ統合と変換を手間のかからないものにしてくれます。Integrate.ioの何百ものすぐに使える統合はこちらでチェックしてください。 ご質問があれば、Integrate.ioがどのようにしてあなたのユニークなETLの課題を解決することができるかを知るために、私たちのチームにご相談ください。
データを統一化して革新を起こすデータチームへ
ソリューションエンジニアによる個別デモと30分のQ&Aセッションを受けることができます



