


先日、Salesforceユーザー向けの新機能をリリースしました。Salesforce PK Chunkingです。ユーザーは、Salesforceから大規模なデータセットを取得する際に、SalesforceソースコンポーネントでPK Chunking機能を有効にすることで、何百万件ものデータセットのロード時や初回取り込み時のデータ量が大きい場合にジョブ実行時間が大幅に短縮されます。
Salesforce PK Chunkingとは?
PK Chunkingは、大規模データセット用に構築された Salesforce の機能です。Salesforce Primary Key (PK) は、オブジェクトのインデックス化されたレコード ID です。PK チャンキングを使用する手順は以下の通りです。
- 対象のテーブルをクエリして、レコードのチャンク数を特定する
- 各チャンクのデータを抽出するためにチャンクサイズでPKを自動的に分割したクエリを実行する
- 最後に結果を結合します。
Salesforce PK Chunkingの有効化
この機能を有効にすると、Salesforce は、Bulk API Query ジョブを複数のバッチに自動的に分割します。そして、それぞれのバッチの進捗状況をポーリングし、すべてが完了した時点で並列で処理することで、ジョブの実行時間を大幅に短縮しています。並列処理はクラスタノード数に依存します。
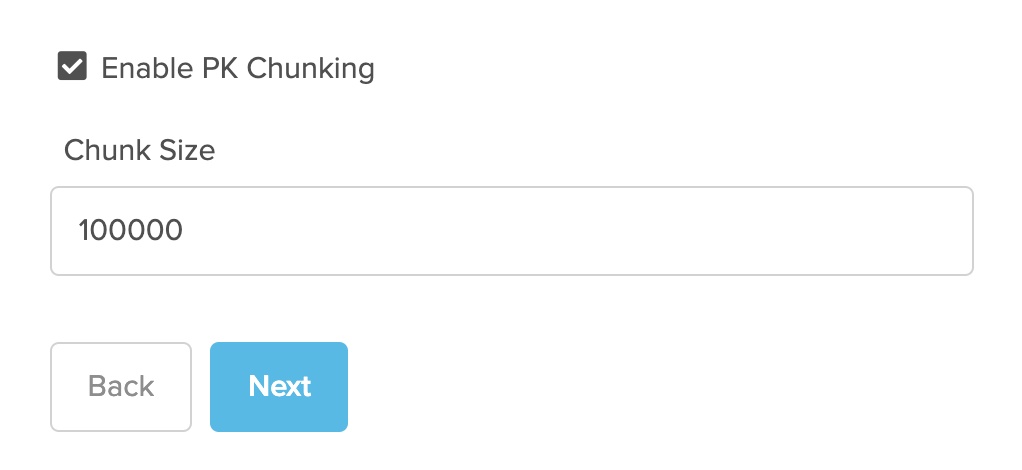
コネクター側で設定されたデフォルトのチャンクサイズは 100,000ですが、'chunkSize' ヘッダーフィールドを使用して、より小さなチャンクや最大 250,000 までの大きなチャンクを設定することができます。
関連ドキュメント: Salesforce PK chunking documentation
Salesforceからのデータ連携にかかる時間を短縮したいといった課題を抱えているお客様は、ぜひIntegrate.ioのオンラインデモにお申し込みいただき、トライアル環境でPK Chunking機能によりどれくらい高速化できるかをお試しください。



